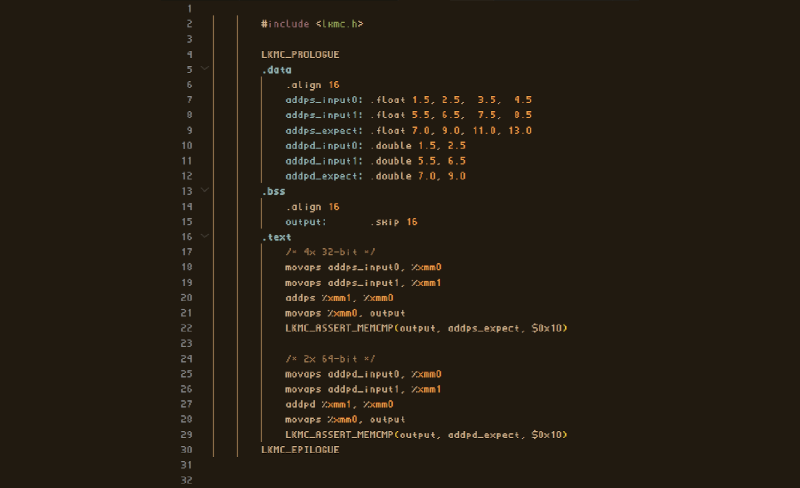
>Part 1: Introduction, how to read SIMD<
Part 2: Basic use, maths, speed up graphics
Part 3: Benchmarking, pushing to the limits
Part 4: Assembly x86, fun instructions
Part 5: History, compatibility, availability
Problem
Imagine a situation where we need to operate on large amounts of data using very trivial operations, for example, for each pixel on the screen, we take an illumination value and multiply that by the albedo value.
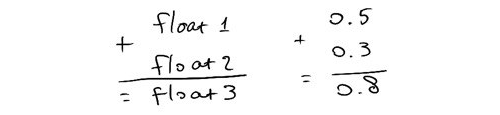
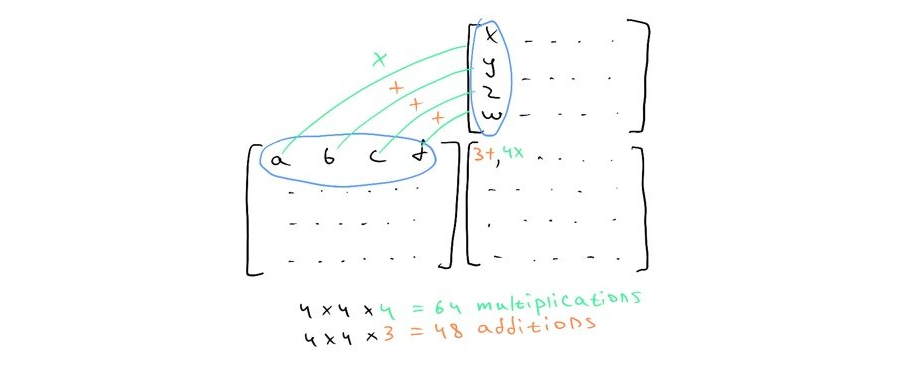
Repeat that for every pixel and you get 2 million multiplications, performed one by one in a row. Another example: we work with matrices and we need to sum or multiply them together. The product of 2 4x4 matrices, most common in 3D applications, takes 64 multiplications and 48 additions. That’s a lot!
What should we do?
We could go several paths:
- Make each operation cheaper (texture mipmaps, approximate with lower precision, etc, + other approaches also apply)
- Don’t do what’s not needed (don’t render what you cannot see, don’t load resources that are not needed right now)
- Reuse previous calculations (cache, precalculate)
- Fake it (LOD, lookup tables, limit approximation, upscaling)
- Perform multiple operations at the same time (GPU, multithreading, decentralizing, SIMD)
Engineers knew about the helplessness of CPUs in the field of 3D graphics. One matrix multiplication is pretty expensive alone, and for believable scenes you need to calculate thousands and millions of them per frame.
What is SIMD?
SIMD stands for Single Instruction Multiple Data1. It is a hardware mechanism that allows processors to perform the same instruction (addition, multiplication, load, store, reciprocal, etc) not one at a time, but 4, 8, or even 16 in parallel, depending on the CPU architecture and supported features. This way at the cost of one multiplication, you can perform a whopping 16 multiplications on modern CPUs or 8 on more-or-less average ones.

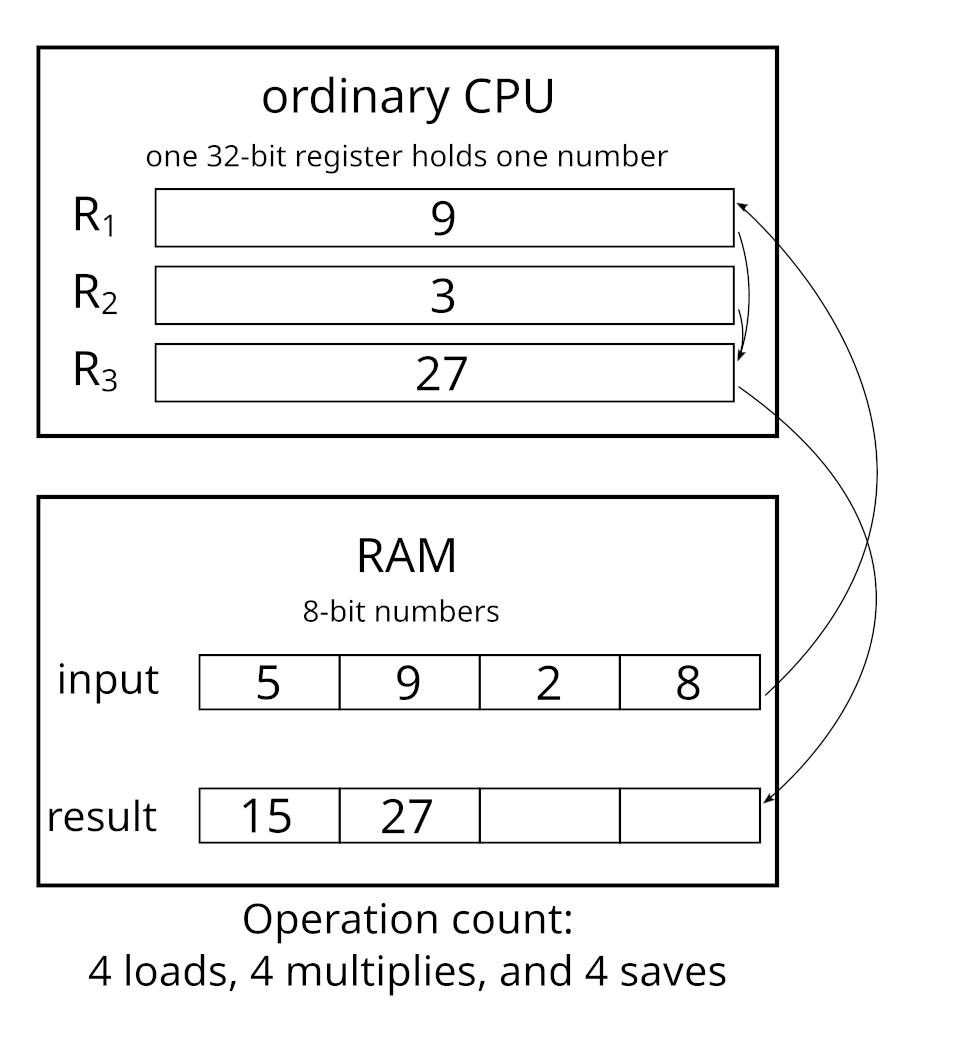
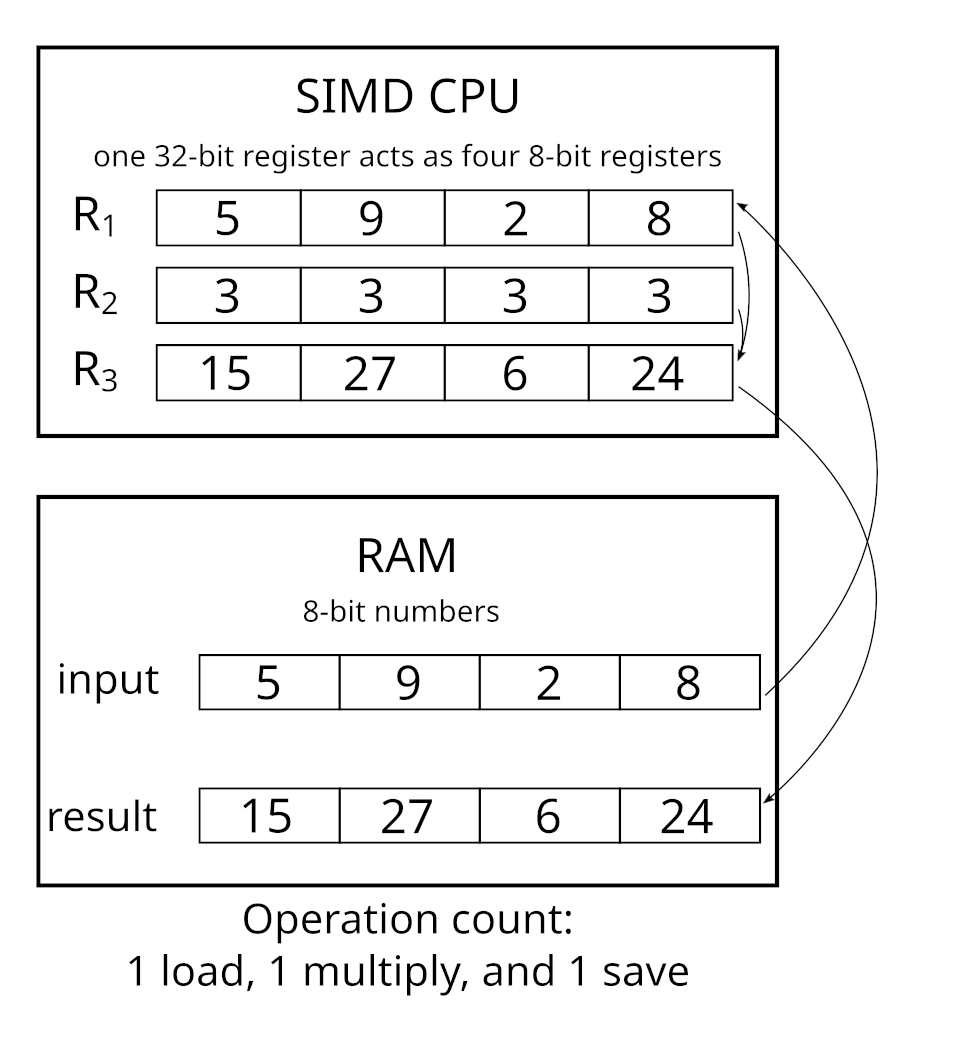
Images are taken from Wikipedia.
Terminology
SSE (Streaming SIMD Extensions) is a very common Intel instruction set extension to the x86 architecture, which operates on 128-bit (16 byte) registers2.
AVX (Advanced Vector Extensions) expanded SIMD capabilities by introducing 256-bit registers. It also introduced a new three-operand instruction format, improving compiler optimization and reducing unnecessary data movement3.
AVX-512 is the latest major extension introducing 512-bit registers. It is pretty rare and is mostly available on high-end desktop and server CPUs due to high power consumption and thermal demands4.
XMM - 128-bit CPU registers2
YMM - 256-bit CPU registers3
ZMM - 512-bit CPU registers4
3DNow!5 is an AMD x86 instructionn set extension for SIMD, which was deprecated in 2010.
Naming convention
In C++ SSE 128-bit operations have _mm prefix
AVX 256-bit ones have _mm256 prefix
AVX-512 uses _mm512 prefix.
| |
Separated with underscore using snake_case, next comes the operation:
| |
Commonly you will see these: add, sub, mul, div, load, store, set, cmp (compare), sqrt (square root)
Next comes data type and layout:
| |
Here is how to read it:
| suffix | meaning |
|---|---|
| ps | packed single-precision floats |
| pd | packed double-precision floats |
| epi32 | extended packed 32-bit integers |
| ss | scalar single float |
| sd | scalar double |
SIMD commonly support integer operations on top of float ones. epi32 is broken down into epi (extended packed integer) and 32 which means 32-bit integer.
Scalars here are opposed to packed values: scalar operations work with just one number while packed ones work on the entire group in parallel6.
Another very common suffix is u and it stands for unaligned memory access7:
| |
For optimal performance, data is commonly aligned to 16 or 32 bytes7 and then the aligned version of memory-access operations are used.
Instruction examples
Take a look at these:4
| |
Some functions of the Vec8f abstraction layer for 256-bit SIMD intrinsics by Agner Fog8 from the Vector Class: Version 2 project:
| |
Intel intrinsics guide9 has a full list of SIMD instructions, do take a look.
How to not use SIMD
For my latest project, a C++ ray tracer I worked on denoising and when I saw it dropping my performance 10 times, my interest for SIMD and the need for it finally matched.
It was my first time really using SIMD, and I did it wrong, here is how:
For the G-Buffer (all data I collect each frame - albedo, light, normals, distances, etc) I have the so-called Array Of Structures, or AoS10. This is the simplest and most naive approach, which makes my data layout linear:
| |
And then I load an AoS to the SIMD registers:
| |
Which is not only ugly, but is also slow and loses the power of SIMD.
First issue is no data locality11: when the order of memory access is linear and consequent, then processor cache prefetches make most memory reads almost free, but when it is accessed in a random or reverse order, the efficiency drops dramatically.
Second issue is less obvious and has to do with AoS. Apparently, there is an alternative: an SoA or Structure of Arrays10. In such case the normals would be stored like this:
| |
You might already see the advantages of this: when CPU loads first value of x into the tNX 256-bit register, it prefetches many more adjacent values of x. At the cost of just one memory access (all others are then retrieved from cache) we manage to populate the entire SIMD register.
With all these issues I made when working with SIMD as a newcomer, it technically did improve performance, but only a little bit, so little, it didn’t really matter. SIMD are very promising though, and as any other tools, have to be used correctly. Follow me through my journey, which I will document in the upcoming articles.
Look into
- Since C++ 26 standard SIMD features are becoming more accessible and easier to use without the need to use intrinsics12
- Newer and more expensive CPUs support up to AVX-512 which is (more than) twice as powerful as AVX
- Many math libraries in many languages have SIMD backend to speedup calculations, such as .NET System.Numerics13 and GLM14
- If you want to benchmark SIMD (or anything else) DO NOT do it manually and rely on a microbenchmarking library, like the one by google.
- Vulkan Guide Intro to SIMD
Sources
All text is written by me; sources, examples and code are referenced inline or at the end of this article. Images are always credited unless I am the author of them.
Code on the cover image is used solely for artistic purposes and is taken from Stackoverflow.